第一节 GIS数据的四个分层与GIS服务
Cesium是一个使用JavaScript编写的基于WebGL的地图引擎。在解读3DTiles之前,可以先了解下GIS数据。从物理角度来看,分为独立数据文件(shp、geojson、tif等),数据库(esri geodatabase的gbd、geopackage等)。GIS之中的两大数据结构:矢量数据和栅格数据。
shp:一种矢量图形格式
geojson:一种对各种地理数据结构进行编码的数据格式
tif:一种标签图像文件格式
gbd:gdb数据库是ESRI特有的数据库,是一些数据集定义、规则和关系的地理数据库方案。
geopackage:一种用于传输地理空间信息的开放格式。
1.矢量数据和栅格数据
矢量数据在GIS之中主要由几何形状组成,包括点、线和多边形(Points, lines and polygons),优势在于可以较为精确地表达大陆、河流、海洋或是其他类型区域的形状和轮廓,结构干净没有冗余。矢量数据储存空间小、对计算机的要求较低。
精确的同时,矢量数据有一个很大的优势在于存储拓扑结构(Topology),拓扑可以帮助探测数据中存在的不合理的交叉、空缺等,所以可以说是非常重要的结构之一。但是,精确也意味着复杂,数据的矢量化是十分耗时,另外矢量数据之间的叠加也比较麻烦,逻辑上并不如栅格数据那样简单、清晰。
栅格数据结构则是以像素格、也就是栅格为基础的。每个栅格会储存相关的数值,并且连成一个完整的平面。点实体由一个栅格像元来表示;线实体由一定方向上连接成串的相邻栅格像元表示;面实体(区域)由具有相同属性的相邻栅格像元的块集合来表示。
栅格数据的最大优势在于叠加,相对应的栅格也可以进行数值的加减乘除。但是栅格数据不能存储拓扑结构,同时由于数据结构比较简单因而相对不如矢量数据灵活。同时,因为栅格在形状表达上的局限性,栅格数据在表现某块区域的时候也不如矢量数据那样精确,若是一块边沿形状弯曲多、不规则的大陆,栅格数据结构对于这块大陆的表现受到栅格本身严整正方形的局限,就自然会有很多不准确的地方。
在数据的存储上形式矢量和栅格结构也不太一样。比如在ArcGIS之中,矢量数据结构下打开一个图层数据表格(Attribute Table),结构大致是某个形状对应的ID,再对应有关的数据。这里的数据可能有不同的种类,比如某个普查区对应的ID后,可以存储收入中位数、本科学位比例等数据。栅格数据结构的图层对应的表格则简单得多,通常一个格子的ID对应一个数值,这个数值是单一的。
术语定义
地理数据 = 空间数据 + 非空间数据,即地理信息,如一座医院、一所学校等
空间数据,即几何数据,描述坐标、形状的数据,也叫空间信息
非空间信息,描述与空间位置无关的数据,如医院名称、成绩单等
2.矢量数据的四个分层
地图层(map)、数据层(data)、要素层(feature)、几何层&属性层(geometry / attribute)
2.1几何/属性层
矢量数据的最底层,包含几何层或属性层。几何层表征位置信息的坐标数据或多个坐标构成的线面。除了几何数据,都是属性数据。
geojson可以包含几何数据 geometry 和属性数据 properties 。
shp文件为二进制文件,至少包含3个, .shp、.shx、 .dbf 。
.shp记录几何数据,.dbf记录属性数据,.shx为连接二者的索引数据
2.2要素层
一个要素表示一个地理实体,有其自己的几何数据和属性数据。
{
"type":"FeatureCollection",
"name":"p",
"crs":{
"type":"name",
"properties":{
"name":"urn:ogc:def:crs:OGC1.3:CRS84"
}
},
"features":[
{
"type":"Feature",
"properties":{
"city":"Beijing",
"editor":"gu",
"adcode":"510000"
},
"geometry":{
"type":"Point",
"coordinates":[
113.22,
23.120
]
}
}
]
}
2.3数据层
n个具有共同类型和数量属性的”feature”(即每一个feature的”properties”的子键名称一致,类型一致),加上一些元数据(坐标系信息,四至等,每种数据格式不太一样),构成一个矢量数据。
一个矢量数据固然可以是一个geojson文件,一个shp文件(由多个同名子文件组成),一个gml文件,一个csv文件,也可以是数据库里的一个表,或者一个要素类(ArcGIS里的gdb)。
2.4地图层
组织起数据,对地理数据进行分析、展示、交互等,设计处一张地图。
地图层包含n个数据,即n个图层,每个图层引用一份数据。
3.栅格数据的四个分层
栅格数据与矢量数据形式上有所区别,但概念上可以归一。可以分为:位置/属性层、像元层、数据层、地图层。
3.1位置/属性层
在栅格中,几何图形所代表的空间数据被像元的中心坐标值代替了,该像元的像元值即属性值。
栅格数据可以是单波段也可以是多波段,可以是浮点数栅格也可以是整数栅格。
栅格数据可以代表的地理数据种类比较多,以单波段数据为例,整数栅格有属性表,可以添加多列属性(即给不同的像元值赋予不同的意义),浮点栅格则不行。
多波段则能实现“同一个像元坐标”“n个像元值”,并且每个像元值独立,不受整数或者浮点数影响。
3.2像元层
像元,包括像元分辨率、像元中心坐标和像元值三大主要数据。
像元层并不像矢量中的要素层表意那么直接,因为单像元表达的地理实体不如一个要素强。但是,多个像元是可以做到一个要素的表达效果的。
比如,在DEM栅格数据中,一个像元可以概括表达这个像元面积这么大的地方的海拔高度。多个连片的像元可以构成一块地区的地形。
但是,和要素层的核心要义是一样的,像元层和要素层都能表达地理实体,把像元的三大主要数据孤立讨论,是不能表达地理实体的。
3.3数据层
数据层和矢量数据的数据层类似,为n个呈矩阵排列的像元构成的图像。
这个图像可以是一层,也可以是多层叠加,只要保证像元中心坐标一致、像元分辨率一致即可。
数据层的物理形式比较简单,除了一些元数据外(坐标系什么的),就是一个体积比较大的数据文件,或者在数据库里的一张表或者一个栅格数据集(Esri gdb)。
若为一个单文件,常见的GIS数据格式为tif,尽管jpg/png/bmp等传统图片格式也可以称作栅格数据,但是它们设计的初衷并不是GIS应用。
在GIS数据服务中,栅格数据切片可以是jpg/png,因为便于网络传输和显示。
3.4地图层
地图层与矢量数据的地图层一致,都为n个栅格数据按一定顺序、符号化构成。
4.GIS服务器
GIS服务,与普通网络服务是一样的。GIS服务器提供GIS数据服务,使得我们可以遵循某些规范访问地理数据或者地理服务。
GIS服务器软件基于HTTP等协议,目前有开源的GeoServer、MapServer,商用的Esri的ArcGIS Enterprise套件等。GIS服务器可以是独立的软件,也可以是某个Web服务器的一个插件。例如,ArcGIS Enterprise套件就是自成一家,GeoServer就是Tomcat的一个war包插件。
5.GIS数据服务
GIS服务可以提供数据服务与计算处理服务。它所扮演的角色,更像是WebGIS中对GIS数据和用户交互之间的一个桥梁,它规范并限制了请求端的操作。GIS数据服务应该属于“地图层”这一层级,因为它可以包括多个数据(图层)。
常用的GIS服务包括:
- 提供访问地理数据的网络地图服务——WMS
- 提供增删改查矢量数据的网络要素服务——WFS
- 网络覆盖服务——WCS
- WMS的变种:网络地图切片服务——WMTS
- 三维场景服务:三大三维数据格式——i3s、3DTiles、s3m
- GIS处理服务——WPS
i3s是一种用树结构来组织大体积量三维数据的数据格式标准,由Esri(arcgis)主推。
s3m是国内北京超图主推的一个三维数据格式标准。
i3s、gltf、s3m三者共同的特点是用树结构来组织数据,用json文件描述数据,用二进制文件来存储具体数据。
第二节 3DTiles数据规范介绍
1.Web中的三维
html5和webgl技术使得浏览器三维成为可能。三维数据(三维模型)是三维可视化重要的一环,但是事实就是:三维数据众多,行业跨界广。
three.js的各种加载器实现了大部分通用三维格式的加载,屏蔽了格式不同的数据结构差异。然而,这样还是不能满足日益增长的效果需求,比如场景一大,模型文件体积变大,解析所耗费的时间越来越长。
webgl,包括所有gpu有关的图形渲染编程,几乎只认这样的三维数据:顶点、顶点颜色、顶点法线、着色语言…
所以,三维图形界的通用格式:glTF应运而生。特点:
面向终点,它按照图形编程所需的格式来存储数据,借以二进制编码提高传输速度。
不再使用面向对象的思维存储三维模型、贴图纹理,而是按显卡的思维存储,存的是顶点、法线、顶点颜色等最基础的信息,只不过组织结构上进行了精心的设计。
面向终点,就意味着可编辑性差,因为渲染性能的提高牺牲了可编辑性,它不再像3ds、dae甚至是max、skp一样容易编辑和转换。
事实上,大多数三维软件提供了glTF格式的转换,或多一步,或一步到位。
2.地理真三维
早年,地理的三维还处于地形三维上,即数字高程模型(DEM)提供地表的高度拉伸。栅格高程数据、等高线、不规则三角网等均是数字高程模型的具体案例。
下图是不规则三角网,也即所谓的三角面片(图形渲染中很常见):
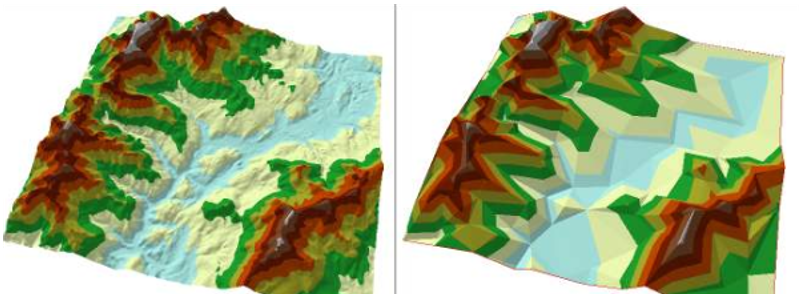
随着学科的融合、计算机技术和硬件的更新换代,使得有模型、有细节的真三维融入到GIS中成为了可能,或者说,计算机技术和硬件的升级,给GIS以更广阔的视角观察世界。

面对大规模精细三维数据的加载,还要照顾到GIS的各种坐标系统、分析计算,gltf这种单个模型的方案显得力不从心。
3.3DTiles介绍和特点
2016年,Cesium 团队借鉴传统2DGIS的地图规范——WMTS,借鉴图形学中的层次细节模型,打造出大规模的三维数据标准—— 3d-Tiles,中文译名:三维瓦片。
它在模型上利用了 gltf 渲染快的特点,对大规模的三维数据进行组织,包括层次细节模型、模型的属性数据、模型的层级数据等。
3dTiles 继承了 gltf 的优点:贴合图形渲染 API 的逻辑,讨 GPU 喜爱,webgl 对其内部组织起来的三维模型数据,不需要转换,可以直接渲染(glTF 的功劳)。

3dTiles 是一种规范,在规范的指导下,各种资源文件可以是独立存在于硬盘中的目录、文件,也可以以二进制形式写入数据库中。
glTF 也是一种规范,它的数据文件不一定就是后缀名为 .gltf 的文件,也不一定只有一个文件(glTF 的文件还可以是二进制文件、纹理贴图文件等)。
3dTiles还有一个特点:那就是不记录模型数据,只记录各级“Tile”的逻辑关系,以及“Tile”自己的属性信息。所谓的模型数据,是指三维模型的顶点、贴图材质、法线、颜色等信息。逻辑关系是指,各级Tile是如何在空间中保持连续的,LOD是如何组织的。属性信息就是物体的属性,如名字、使用年限等。
3dTiles的特点总结如下:
- 三维模型使用了 glTF 规范,继承它的渲染高性能
- 只记录各级Tile的空间逻辑关系(如何构成整个3dtiles)和属性信息,以及模型与属性如何挂接在一起的信息
4.LOD细节层次
LOD(level of detail):是指根据物体模型的结点在显示环境中所处的位置和重要度,决定物体渲染的资源分配,降低非重要物体的面数和细节度,从而获得高效率的渲染运算。在OSG的场景结点组织结构中,专门提供了场景结点osg::LOD来表达不同的细节层次模型。其中,osg::LOD结点作为父节点,每个子节点作为一个细节层次,设置不同的视域,在不同的视域下显示相应的子节点。
数据分页:在城市三维场景中可以采用数据分页的方式进行动态调度。这里“分页”的意思是随着视口范围的变化,场景只加载和渲染当前视口范围内数据,并将离开视口范围内的数据清除内存(可以设定不同的数据卸载策略),不再渲染。保证内存中只有有限的数据量,场景的每一帧也只有有限的数据被送到图形渲染管道,从而提高渲染性能。
动态调度:OSG(一种三维渲染引擎)源代码中提供PagedLOD来进行模型的动态调度。在不同的视域下,PagedLOD动态读取不同细节层次的结点模型,实现了分页LOD显示。OSG内部采用osgDB::DatabasePager类来管理场景结点的动态调度,场景循环每一帧的时候,会将一段时间内不在当前视图范围内的场景子树卸载掉,并加载新进入到当前视图范围的新场景子树。OSG采用了多线程的方式来完成上述工作。
第三节 三维瓦片 Tileset和Tile
1.3DTiles数据集
3DTiles数据集包括tileset.json文件,以及各级瓦片文件。
3dTiles数据集在文件夹中至少有一个tileset.json文件,作为整个数据集的入口。它是一个 json 文件,描述了整个三维瓦片数据集,它记录的是各级瓦片的“逻辑信息”,还包括一些其他的元数据。而“属性信息”、“嵌入的gltf模型” 则位于各个二进制瓦片文件中,这些二进制文件则由 tileset.json 中的瓦片中的 uri 来引用。
2.瓦片
瓦片切割了三维数据,允许三维数据进行细分。网速是有限的,在加载超大规模的三维模型数据时,不可能把一个模型全部下载下来再渲染,非常耗时。但是一点一点出现,视野范围外的“瓦片”则干脆就不下载、渲染,性能、视觉都有提高。这就是瓦片的设计优点。
传统的二维地图瓦片,叫做 WMTS 或 TMS,这个 “T” 就是 Tile 的意思。3dTiles就是把空间进行切块,每个块叫做 “tile”,也即瓦片。
3.tileset.json
tileset.json是一个三维瓦片数据集的入口文件。
{
"asset": {
"version": "1.0"
},
"geometricError": 287.736328,
"root": {
"boundingVolume": {
"region": [
1.806639,
-0.000234,
1.806672,
-0.000204,
99882.016518,
99904.602379
]
},
"geometricError": 287.736328,
"children": [
{
"boundingVolume": {
"region": [
1.806639,
-0.000234,
1.806672,
-0.000204,
99882.016518,
99904.602379
]
},
"geometricError": 4,
"content": {
"uri": "texture_ABAABA.json"
}
}
]
}
}
root对象中有一个content,内有uri属性,其就记录了根瓦片的二进制数据文件的URL,这个URL是个相对路径,相对于 tileset.json 文件。
1)顶级属性
通常来说,tileset.json必须存在几个顶级对象
- asset
- root
- geometricError
asset 对象,记录了整个数据集的声明和归属数据,类似于数据声明,能在此写入 version、tilesetVersion 等属性,当然也可以像上方的例子一样,写入生成工具、gltf朝向等信息。
root 对象,即这个数据集的根瓦片,每个3dTiles数据集必须有一个 root 对象。
geometricError 几何误差,数值的大小能控制 LOD 的显示隐藏,且这个数值父级瓦片一定比子级瓦片大。
2)root瓦片及其children
树结构对于三维空间数据的组织有很大的优势。3dTiles在空间上允许数据集使用如下几种树结构:
- 四叉树
- 八叉树
- KD树
- 格网结构
四叉树允许使用传统的均匀四叉树,也允许使用松散四叉树等变种(例如,允许子节点,即子瓦片允许存在空间范围重叠)。

上图为两个子瓦片在空间上存在部分重叠,照顾到了建筑物不可能严格切分的特点。
四叉树对在高度上不太好切分的数据比较适合,而如果追求极致的空间分割和分级(例如点云数据),那么八叉树更合适。
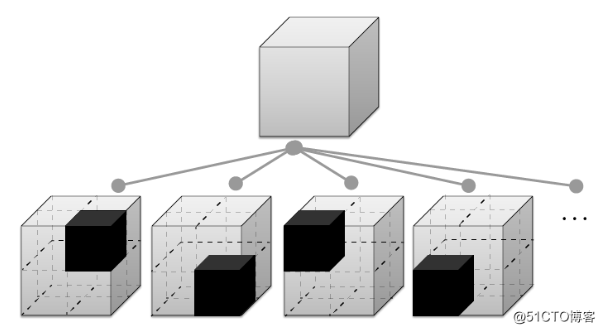
八叉树也允许使用各种变种。
kd树比较难理解,在此不作展开,这也是一种有趣的空间结构分割的数据结构。
格网结构的树允许瓦片存在多个子瓦片:

通常出现在倾斜摄影数据上,但是这会导致网络请求过多的问题。
3)坐标系统
可以用简单的两位数、三位数:经纬度,还有一个高度来标识地球表面附近的任何一个点。经纬度的范围不超过三位数,而用米作单位的空间直角坐标系来描绘地球,数字太大,不好记忆。在GIS中,WGS84就是一个用经纬度来标识空间坐标的“地理坐标系,Geographic Coordinate System”。
由于历史上对地球测量的技术不同,科学家制造了多个长半轴短半轴不太一样的“椭球”,来模拟地球的形状。目前,最具代表性的就是两个以地球质心为中心的椭球体:
- WGS84椭球体
- 中国国家2000椭球体(即CGCS2000)
基于椭球体,我们允许有多种不同的坐标系定义,WGS84坐标系其实并不太严谨。基于WGS84椭球(长短半轴等信息自行查询哈),可以使用球面坐标度量,即经纬度,还有一个从质心射向椭球面上的点的“椭球高度”射线,来记录第三维高度数据。
介绍了那么多,3dTiles其实采用的是WGS84椭球,但是并未采用经纬度记录数据:因为相对于精细三维模型来说,经纬度不足以提供足够精确的空间分割(要照顾图形显示问题)。所以,同样是那个形状,3dTiles使用了同一个WGS84椭球,但是更方便计算的坐标:空间直角坐标。
用经纬度记录数据的WGS84坐标系,WKID是4326,用地心为坐标原点的空间直角坐标来记录数据的坐标系,WKID是4979.
3dTiles 用的就是4979坐标系。
4.Tile——构成3dtiles的成员:瓦片
1)二进制文件类型
通常,瓦片对象会引用一个二进制的瓦片数据文件。如:在conetent.uri 属性中引用 .b3dm 文件。
瓦片所引用的二进制的瓦片数据文件,有四种类型:
| 格式 | 用途 |
|---|---|
| Batched 3D Model (.b3dm) | 多种三维模型格式,例如有纹理的地形数据,包含内外结构的三维建筑,大范围的模型数据,传统三维建模数据、BIM数据、倾斜摄影数据 |
| Instanced 3D Model(.i3dm) | 实例化三维模型,例如森林、路灯和垃圾桶等城市附属物、设备零部件等 |
| Point Cloud(.pnts) | 点云模型,海量点数据 |
| Composite(.cmpt) | 复合模型,把上述多个不同格式的文件组织为一个文件,允许一个cmpt文件内嵌多个其他类型的瓦片 |

2)瓦片对象内容
瓦片对象的记录信息:
"children": [
{
"boundingVolume": {
"region": [
1.806639,
-0.000234,
1.806672,
-0.000204,
99882.016518,
99904.602379
]
},
"geometricError": 4,
"content": {
"uri": "texture_ABAABA.json"
}
}
]
这是一个children下的第一个瓦片,观察不难得知,与root瓦片其实在属性上长得一模一样。
瓦片对象都有如下属性:
- boundingVolume:空间范围框,允许有box、sphere、region三种范围框,但是只能定义一种
- geometricError:几何误差
- 其他属性:viewerRequestVolume、transform
瓦片对象记录的就是瓦片的元数据,真正瓦片的本体数据在content所引用的二进制文件中。
3)瓦片的灵活性
Tile不仅仅可以在其uri属性中引用 诸如 .b3dm、.i3dm、.pnts等二进制瓦片数据文件,还可以再引用一个 3dTiles!
如 从osgb倾斜摄影数据转换而来的3dtiles数据,可以在root瓦片的第一个child瓦片中,引用另外一个json文件。这证明了两件事:
- 3dTiles的文件名可以不是tileset.json
- 3dTiles允许套娃
原则上,只要被引用的子一级3dtiles 不可以循环引用父级3dtiles
第四节 内嵌在瓦片文件(二进制)中的两大数据表
1.数据与模型
1)数据与模型的联系
瓦片的三维模型实际上是由gltf承担起来的(作为glb格式嵌入到瓦片二进制文件中),那么,除了模型数据,肯定模型自己本身也有属性数据的。
就比如,门有长宽高、密度、生产日期等信息,楼栋模型有建筑面积、楼层数等信息。
所以,“属性数据” 和 “模型” 是如何产生联系的呢?

只需把模型的几何数据作为一个属性,写入属性数据中,即把属性数据和几何数据并列。
但是,在3dTiles中,模型数据是以glb的形式嵌入在瓦片文件中的(点云直接就写xyz和颜色信息了),模糊了二维中“要素”的概念,而且gltf规范看起来并没有所谓的“要素”的概念,仅仅是对GPU友好的vertex、normal、texture等信息。
如何让gltf模型的每一个模型,甚至每一个三角面,甚至每一个顶点打上“我属于哪个模型”的印记呢?在表中加一个batchId属性值。
2)两个重要的表
3dTiles 规范本身不包含模型数据的定义,它仅仅记录模型变成瓦片后的空间组织关系、模型与其属性数据之间的关系。
所以,3dTiles 规范在瓦片二进制数据文件中,使用了两个重要的表来记录这种 ”模型与属性“ 的联系:
- FeatureTable(要素表)
- BatchTable(批量表)
2.二进制文件结构
瓦片二进制数据文件的大致字节布局结构如下:

瓦片引用的二进制文件有4种,即:b3dm、i3dm、pnts、cmpt。除去复合类型cmpt,前三种的大致布局见上图。
每一种瓦片二进制数据文件都有一个记录该瓦片的文件头信息,文件头包括若干个因瓦片不同而不太一致的数据信息,紧随其后的是两大数据表:FeatureTable(我翻译其为:要素表)、BatchTable(我翻译其为:批量表)。
这两个表既然是二进制的数据,尽管它名字里带“表”,但是却不是二维表格,它更多的是一些 键值 信息。
1)记录渲染相关的数据:FeatureTable,要素表
在 b3dm 瓦片中,要素表记录这个批量模型瓦片中模型的个数,这个模型单体在人类逻辑上不可再分。如:在房屋级别来看,房子并不是单体,构造它的门、门把、窗户、屋顶、墙等才是模型单体;但是在模型壳子的普通表面建模数据中,房子就是一个简单的模型。
要素表还可以记录当前瓦片的中心坐标,以便gltf使用相对坐标,压缩顶点坐标数字的数据量。
要素表记录的是与渲染有关的数据。即:
要素表,记录的是整个瓦片渲染相关的数据,而不是渲染所需的数据。
渲染相关,即有多少个模型,坐标是相对的话相对于哪个中心,如果是点云的话颜色信息是什么以及坐标如何等;
渲染所需,例如顶点信息、法线贴图材质信息均有glb部分完成。
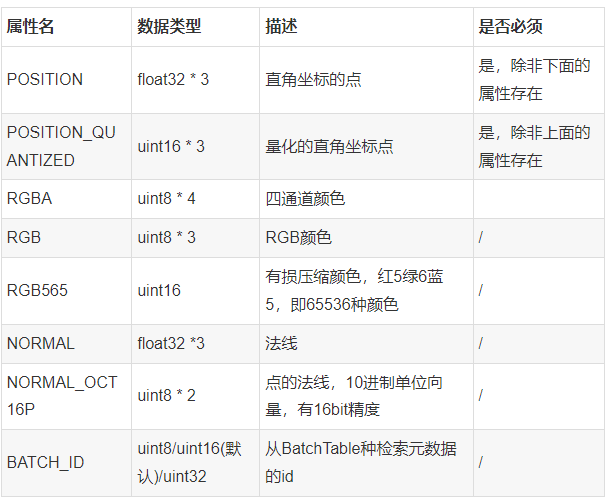
以pnts(点云瓦片)举例,它的要素表允许有两大类数据:点属性、全局属性
- 点属性:记录每个点云点的信息
- 全局属性:记录整个点云瓦片的信息
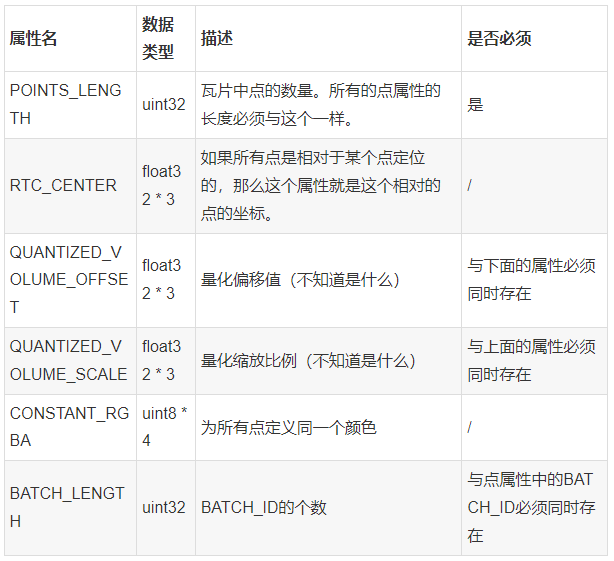
可以看出点云因为没有使用gltf模型(也没必要),把点云要渲染到屏幕上所需的坐标、法线、颜色等信息写在了要素表中。
在一个瓦片中,一个三维要素(GIS中的通常叫法)= 一个模型(图形学、工业建模叫法) = 一个BATCH(3dtiles叫法)
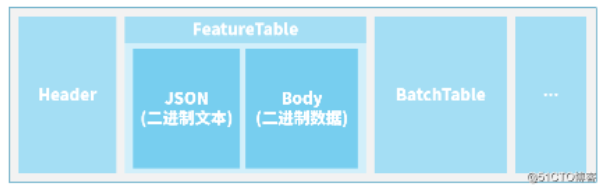
要素表的结构:JSON描述信息+要素表数据体
要素表紧随在若干个字节的文件头后,它本身还可以再分为 二进制的JSON文本头 + 二进制的数据体。如下图所示:
2)记录属性数据:BatchTable,批量表
如果把批量表删除,那么3dTiles数据还能正常渲染。
批量表就是所谓的模型属性表,批量表中每个属性数组的个数,就等于模型的个数,因为有多少个模型就有多少个对应的属性!
(嘿嘿,其实也有例外的情况,我们到后续聊3dtiles数据规范的扩展能力时,再把这个坑填上,不然怎么说3dtiles很灵 [keng] 活 [die] 呢)
批量表相对比较自由,只要能与模型对得上号,想写啥就写啥。
批量表中的属性数据 ↔ 模型的关联
由gltf 数据规范可知,gltf 数据有三层逻辑:Node ← Mesh ← Primitive。
其中,Primitive 即 gltf 数据规范中最小的图形单位,其顶点定义由其下的 attributes 对象下 POSITION 属性来寻找访问器(Accessor),从而获取到数据。

获取到 POSITION 、indices 对应的访问器、缓存视图、缓存文件后,即可获取 gltf 模型的所有顶点,即几何模型,即三维要素的几何数据。
现在问题来了,如何将这些顶点 “打” 上一个印记呢?
Cesium团队在设计 3dtiles 规范的时候充分利用了 gltf 规范的特点:开源。因此,每一个 primitive 被在其 attributes 中添加了额外的访问器:_BATCHID。

它与 POSITION 等没什么两样,同样会占用一部分数据。
如果每一个顶点都有一个所谓的 _BATCHID 对应,给出任意点,就能知道这个点的 _BATCHID,从而就知道这个点属于哪一个 BATCH 。
一个 BATCH (即三维要素)用自己的 BATCHID 与几何数据一一对应,属性数据也与这个 BATCHID 一一对应,由传递关系,那么三维的几何数据 (gltf) 也就能和 属性数据 (批量表) 一一对应了。
不过遗憾的是,并不是所有的瓦片都有 gltf 模型,例如pnts瓦片。所以这个 几何 与 属性 两大数据如何关联,在之后需要具体问题具体分析。
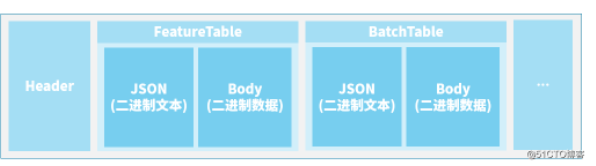
批量表的结构:JSON描述信息+批量表数据本体
与 要素表 很像,批量表也是由: 二进制的JSON文本头 + 二进制的数据体 构成的。如下图所示:
关于两个表的更深层次的数据内容,例如如何承载模型与模型之间的逻辑关系,如何记录使用 Google 压缩算法的模型数据,后面再具体介绍。
3)查询瓦片的批量表
通常在Cesium中使用 点击 事件,来获取一个 BATCH,即三维要素。在Cesium API中,这个被叫做:Cesium3DTileFeature。
那么,这个 Cesium3DTileFeature 就能访问到它自己的批量表中的属性数据:
const handler = new Cesium.ScreenSpaceEventHandler(viewer.canvas);
handler.setInputAction(function(movement) {
let feature = scene.pick(movement.endPosition);
if (feature instanceof Cesium.Cesium3DTileFeature) {
let propertyNames = feature.getPropertyNames();
let length = propertyNames.length;
for (var i = 0; i < length; ++i) {
let propertyName = propertyNames[i];
console.log(propertyName + ': ' + feature.getProperty(propertyName));
}
}
}, Cesium.ScreenSpaceEventType.LEFT_CLICK);
用到了 Cesium3DTileFeature.getPropertyNames() 方法获取批量表中所有属性名,用了 Cesium3DTileFeature.getProperty(string Name) 来获取对应属性名的属性值。
第五节 b3dm瓦片二进制数据文件结构
B3dm,Batched 3D Model,成批量的三维模型的意思。
倾斜摄影数据(例如osgb)、BIM数据(如rvt)、传统三维模型(如obj、dae、3dMax制作的模型等),均可创建此类瓦片。
瓦片文件二进制布局(文件结构):
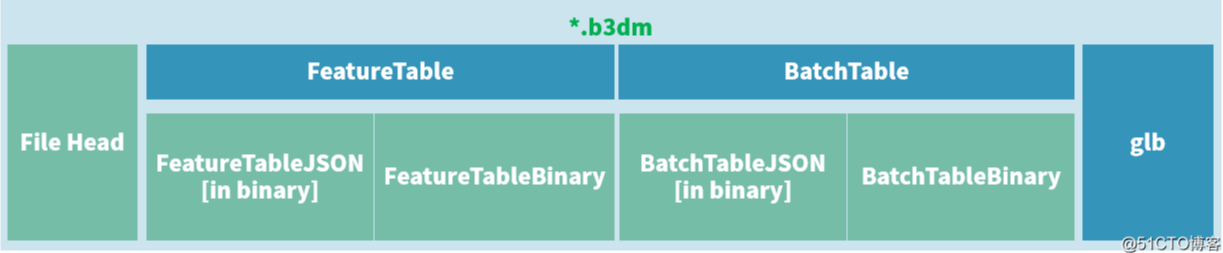
1.文件头:占28字节(byte)
位于b3dm文件最开头的28个字节,是7个属性数据:
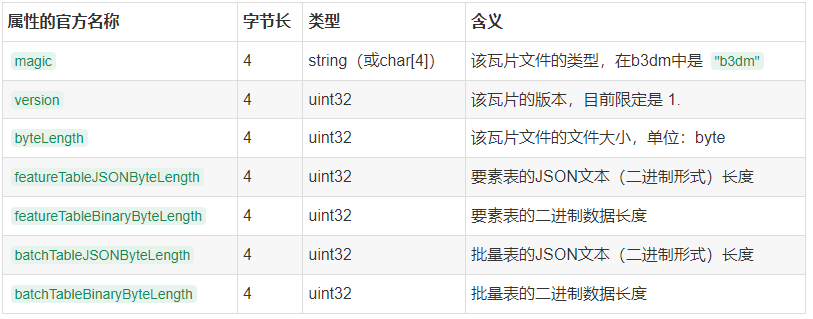
其中,
byteLength = 28 + featureTableJSONByteLength + featureTableBinaryByteLength + batchTableJSONByteLength + batchTableBinaryByteLength + glb的字节长度
2.要素表
要素表,记录的是整个瓦片渲染相关的数据,而不是渲染所需的数据。
那么,b3dm瓦片中的要素表会记录哪些数据呢?
1)全局属性
什么是全局属性?即对于瓦片每一个三维模型(或BATCH、要素)或者直接对当前瓦片有效的数据,在b3dm中,要素表有以下全局属性:

注意,如果glb模型并不需要属性数据,即要素表和批量表有可能是空表,那么 BATCH_LENGTH 的值应设为 0 .
2)要素属性
对于每个模型(BATCH、要素)各自独立的数据。在b3dm中没有。
我们回忆一下要素表的定义:与渲染相关的数据。
b3dm瓦片与渲染相关的数据都在glb中了,所以b3dm并不需要存储每个模型各自独立的数据,即不存在要素属性。
在i3dm、pnts两种瓦片中,要素属性会非常多。
3)全局属性的存储
全局属性存储在 要素表的JSON中,见下文:
- JSON头部数据
由上图可知,文件头28字节数据之后是要素表,要素表前部是 长达 featureTableJSONByteLength 字节的二进制JSON文本,利用各种语言内置的API可以将这段二进制数据转换为字符串,然后解析为JSON对象。
例如,这里解析了一个b3dm文件的 要素表JSON:

那么,此b3dm瓦片就有4个模型(4个要素,或4个BATCH),其 batchId 是0、1、2、3.
要素表的二进制本体数据
无。
注:
当要素表的 JSON 数据以引用二进制体的方式出现时,数据才会记录在要素表的二进制本体数据中,此时JSON记录的是字节偏移量等信息。
但是在b3dm瓦片中,要素表只需要JSON就可以了,不需要自找麻烦再引用二进制数据,因为BATCH_LENGTH 和 RTC_CENTER 都相对好记录,一个是数值,一个是3元素的数组。
在下面的要介绍批量表中,就会出现 JSON 数据引用二进制体的情况了。在 i3dm 和 pnts 瓦片中,要素表 JSON就会大量引用其二进制体。
3.批量表
批量表记录的是每个模型的属性数据,以及扩展数据。
要素表和批量表唯一的联系就是 BATCH_LENGTH,在 i3dm 中叫 INSTANCE_LENGTH,在 pnts 中叫 POINTS_LENGTH。
要素表记录了有多少个模型(BATCH、要素),那么批量表每个属性就有多少个值。
1)JSON头部数据
批量表的JSON:

这个批量表的JSON有两个属性:height、geographic,字面义即模型的高度值、地理坐标值。
height 属性通过其 componentType 指定数据的值类型为 FLOAT,通过其 type 指定数据的元素类型为 SCALAR(即标量)。
geographic 属性通过其 componentType 指定数据的的值类型是 DOUBLE,通过其 type 指定数据的元素类型为 VEC3(即3个double数字构成的三维向量)。
byteOffset ,即这个属性值在 二进制本体数据 中从哪个字节开始存储。
从上表可以看出,height 属性跨越 0 ~ 39 字节,一共40个字节。
通过 FeatureTableJSON 可以获取 BATCH_LENGTH 为10,那么就有10个模型,对应的,这 40 个字节就存储了10个 height 值,查相关资料得知,FLOAT类型的数据字节长度为 4,刚好 4 byte × 10 = 40 byte,即 height 属性的全部数据的总长。
geographic 属性也同理,VEC3 代表一个 geographic 有3个 DOUBLE 类型的数字,一个 DOUBLE 数值占 8byte,那么 geographic 一共数据总长是:
type × componentType × BATCH_LENGTH = 3 × 8byte × 10 = 240 byte.
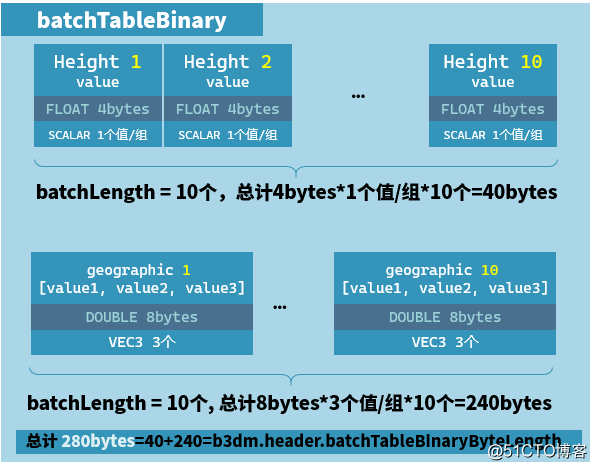
事实上,两个属性的总长是 40 + 240 = 280 byte,与 b3dm 文件头中的第七个属性 batchTableBinaryByteLength = 280 是一致的。
2)二进制本体数据
二进制本体数据即批量表中每个属性的顺次存储。
能不能不写二进制本体数据?可以。如果你觉得数据量比较小,可以直接把数据写在 BatchTableJSON 中,还是以上述两个数据为例:

注意:
同样是一个数字,二进制的JSON文本大多数时候体积会比二进制数据大。因为JSON文本还包括括号、逗号、冒号等JSON文本必须的符号。对于属性数据相当大的情况,建议使用 JSON引用二进制本体数据的组织形式,此时JSON充当的角色是元数据。
对于属性的值类型是 JSON 中的 object、string、bool 类型,则必须存于 JSON 中,因为二进制体只能存 标量、234维向量四种类型的数字数据。
4.内嵌的glb
二进制gltf数据,在要素表和批量表之后。它可以嵌入几乎所有哦的几何、纹理和动画,或者它可以引用外部源来获取部分或全部数据。每个顶点都有一个batchId属性,指示它所属的模型。
具有三个模型的批次顶点可能如下所示:

顶点不需要按 排序batchId,所以下面的也可以:

请注意,一个顶点不能属于多个模型;在这种情况下,需要复制顶点,以便batchId可以分配 s。
通过提供属性语义以及访问器的索引,在batchId glTF网格中指定参数,如_BATCHID batchId

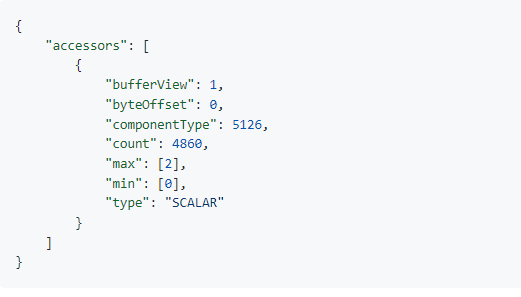
accessor.type必须是 的值"SCALAR"。所有其他属性必须符合 glTF 模式,但没有其他要求。
当 Batch Table 存在或BATCH_LENGTH属性大于0时,该_BATCHID属性是必需的;否则,它不是。
5.字节对齐与编码端序
1) JSON二进制文本对齐
FeatureTableJSON、BatchTableJSON的二进制文本,最后一个字节相对于整个b3dm文件来说,偏移量必须是8的倍数。
如果不对齐,必须用二进制空格(即 0x20)填够。
起始偏移量不用要求 8byte 对齐,因为 FeatureTableJSON 之前是28byte的 文件头,为了凑齐8倍数对齐,文件头和 FeatureTableJSON 还要塞4个字节填满,那就有点多余了。
末尾对齐,即 (28 + ftJSON长)能整除8,(28 + ftTable长 + btJSON长)能整除8.
2)数据体的起始、末尾对齐
二进制数据体,无论是要素表、批量表,首个字节相对于b3dm文件的字节偏移量,必须是8的倍数,结束字节的字节偏移量,也必须是8的倍数。
如果不满足,可以填充任意数据字节满足此要求。
特别的,二进制数据体中,每一个属性值的第一个数值的第一个字节的偏移量,相对于整个b3dm文件,必须是其 componentType 的倍数,如果不满足,则必须用空白字节填满。
例如,上述 height 属性所在的批量表二进制数据体,理所当然位于批量表JSON之后,而批量表的JSON又是8byte对齐的,假设批量表的数据体起始字节是800,那么 height 的第一个值起始字节就是 800,由于 height 属性的 componentType 是 FLOAT,即 4字节,800 ÷ 4 能整除,所以没有问题。
但是,假如 换一个属性,其 componentType 是 BYTE,即 1字节,那么假设第二个属性的 componentType 是 DOUBLE,即 8字节,就会出现 第二个属性的第一个值起始偏移量是810,810 ÷ 8 并不能整除,必须补齐 6个空白字节,以满足第二个属性第一个值的起始偏移量是 810+6 = 816字节。
3)编码端序
要素表、批量表的二进制数据,无论是JSON还是数据体,均使用小端序编码(LittleEndian)。
6.扩展数据(extensions)与额外补充信息(extras)
其实,无论是要素表,还是批量表,都允许在JSON中存在扩展数据,以扩充当前瓦片模型的功能,而并不是单一的一个一个模型顺次存储在瓦片文件、glb中。



